Tool Calling at Scale: Navigating the Trade-offs Between Cloud and Edge Agents

When building AI agents that interact with the real world, tool calling is the bridge between language understanding and action. Whether your agent queries databases or controls smart home devices, it needs to invoke the right function with the correct parameters. At Liquid AI, we are very deep in this problem space, building foundation models that need to perform tool calling both in the cloud and on device. The challenges, it turns out, are quite different at each end of the spectrum.
The Cloud Model Dilemma: Context as Currency
Large cloud models handle tool calling by including tool definitions directly in their context window. You describe your available functions, their parameters, and expected behaviors, and the model learns to invoke them appropriately. This approach works well when you have a handful of tools.
The trouble begins when your agent needs access to hundreds of tools. Every tool definition consumes tokens. Every parameter description, every example, every edge case you document inflates your context. This has three cascading effects: inference becomes slower due to the increased prefill computation, costs rise proportionally with token count, and perhaps most concerning, model performance itself begins to degrade.
Context rot
This last point above deserves further discussion. There is a phenomenon in the ML community sometimes referred to as “context rot,” where even the most capable large language models start to lose coherence and accuracy as context length grows. For current cloud models, this happens typically in the 100-500k tokens context range. The model may begin to hallucinate more, becomes less reliable with parameters, or simply failing to follow instructions buried deep in a long prompt. Pushing this phenomenon to only appear at even longer context length or addressing it fundamentally is an open research problem.

One emerging solution is what we might call a “tool discovery” pattern: rather than loading all tool definitions upfront, you provide the model with a meta-tool that can search and retrieve relevant tool definitions on demand. The agent first queries which tools might be relevant to the current task, then loads only those definitions into context. Anthropic provides such a tool for the Claude models.
This approach reduces context length, but introduces its own complexity. You now have a two-stage process where the first stage (tool discovery) becomes a potential point of failure. If the discovery step misses a critical tool, your agent will fail regardless of how capable the underlying model is. For instance, if the user wants to “find nearby shops” but the corresponding tool is named “locate_entity” the matching process may not be 100% successful.
The Edge Challenge: The Fine-tuning Question
Now consider on-device agents powered by small language models (SLMs). The constraints are similar in nature but differ in one key aspect: Parameter count. The hardware constraints on memory and compute allow us to only run a small model. Since SLMs have a fraction of the parameters of their cloud counterparts, their out-of-the-box “zero-shot” function calling capabilities cannot match the reliability of larger cloud models. As a result, SLMs for on-device agents need to be fine-tuned for their specific domain or task, to achieve the task-specific performance on par with the zero-shot capabilities of larger models, e.g., an SLM fine-tuned to control smart home devices.
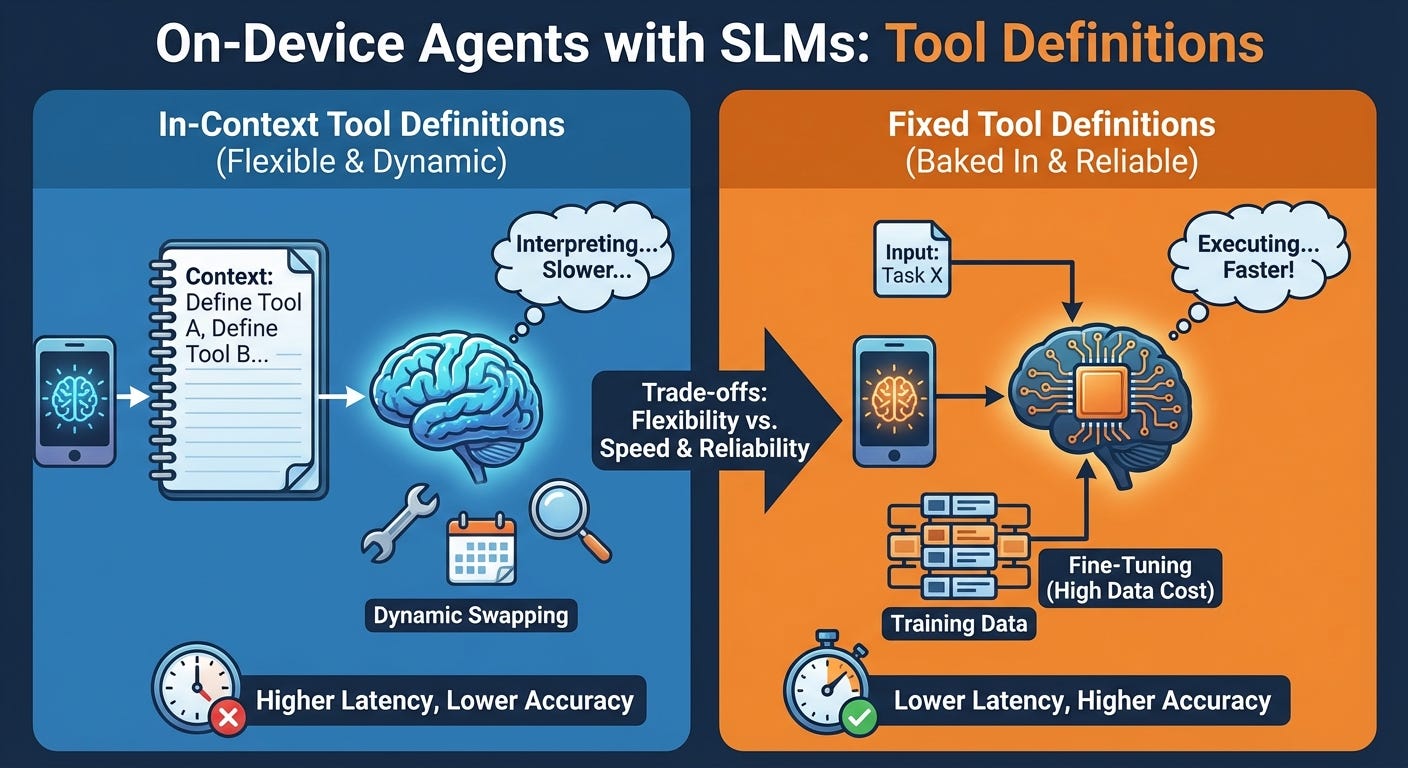
Since the models need to be fine-tuned, this leads to the: do you put tool definitions in context, or do you “bake them in” through fine-tuning?
The in-context approach preserves flexibility. You can dynamically swap tools based on the current task, add new capabilities without retraining, and maintain a single model that adapts to different use cases. However, SLMs are inherently less robust than massive cloud models. Their tool calling accuracy with in-context definitions tends to be lower, and the performance penalty of longer contexts is proportionally more severe on resource-constrained devices. More prefill means more latency and decode speed degrades at longer sequence lengths.
Fine-tuning offers a different set of trade-offs. By training the model directly on your tool calling patterns, you can achieve substantially higher accuracy and reliability. The model internalizes the function signatures, understands the expected parameters, and executes with minimal overhead since no tool definitions need to be processed at inference time. The result is faster, more reliable tool calling.
The cost? Data. Fine-tuning requires high-quality examples of tool usage, and collecting this data at scale is often the biggest bottleneck in the entire pipeline. You also lose the dynamic flexibility of the in-context approach. Adding a new tool means collecting new data and retraining the model. If you need to support different tool sets for different deployments, you may end up managing multiple fine-tuned variants.
A Practical Strategy
Our experience suggests a staged approach works well in practice. Start with in-context tool definitions. This lets you iterate quickly, test different tool designs, and validate that your agent architecture works end-to-end. Treat this as your prototyping phase.
As your tool set stabilizes and you gather real usage data, identify the tools that are most critical to your application. These become candidates for fine-tuning. If you find that context length is becoming a bottleneck, or if accuracy on certain tools is not meeting your requirements, that is your signal to invest in training data collection and model specialization.
Another factor that we should not discount for on-device agents is that not all edge devices are made equal. The compute and memory available on a Raspberry Pi differs immensely from a much more powerful NVIDIA Jetson Nano or a high-end Qualcomm SoC. On the latter devices we have more room and flexibility to push the in-context solution while on a Raspberry Pi class hardware we almost certainly will converge to a “baked-in” approach.
Token Efficiency: Pythonic Tool Calling
One detail worth sharing from our work at Liquid: we do not exclusively use the standard JSON-based format for tool calling. Instead, we have adopted a Python-based syntax for function invocation.
The common argument for JSON is that language models have seen plenty of it during pretraining, so they understand the syntax well. This is true. But the same argument applies to Python, and Python has one advantage: it is far more token-efficient for expressing function calls.
Consider the overhead in a typical JSON tool call: curly braces, square brackets, quoted keys, quoted string values, commas after every element. A Python function call expresses the same information with less syntactic ceremony. When you are optimizing for on-device deployment, the extra tokens add up quickly.
By choosing Python syntax, we get the best of both worlds: a format the model has deeply internalized from pretraining, combined with a compact representation that saves tokens at inference time.
Looking Forward: Hierarchical Agents and Nested Intelligence
The most interesting direction we see emerging is hierarchical agent architectures, and protocols like MCP are making this increasingly practical.
Consider a tool that is not just a function, but an entire agent with its own language model, its own context, and its own sub-tools. Your primary agent calls an MCP endpoint, but behind that endpoint sits another LLM orchestrating a specialized domain. That sub-agent can spawn its own tool calling sessions, manage its own state, and return synthesized results to the parent.
This pattern enables a lightweight orchestrator to delegate to specialized sub-agents, one for code execution, another for data analysis, another for external APIs, each maintaining its own context and toolset. The parent agent does not need to understand each domain’s details or fill its context with sub-task-specific information, thus keeping focus and a short context.
This approach works for both cloud and edge models, since on the edge we can have different SLMs for the different agents, each fine-tuned and optimized for their own sub-task.
We are still in the early days of understanding how to orchestrate these hierarchical systems reliably, but the direction is clear: the future of tool calling might be deeply nested.
We are hiring researchers and engineers who are excited about these challenges. If building the next generation of efficient AI systems sounds interesting to you, we would love to hear from you.
Liquid AI is building foundation models designed for efficiency and real-world deployment. Learn more at liquid.ai